- Platform
- Solutions
Data Hub
Business-specific models to fix the ugly data problem
Customer Hub
Segment, Personalize, Engage - Witness AI in Action.

Personalization
Forecast & tailor content that speak your customers

Audience Builder
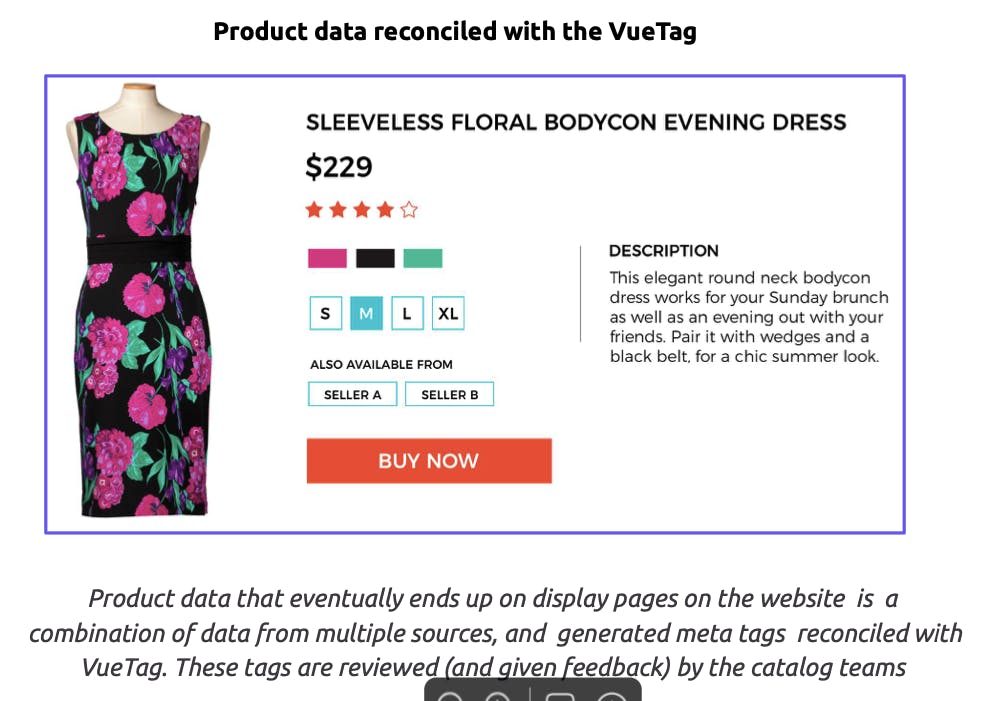
360° customer view via unified micro profiles

Journey Orchestration
Tailor experiences across all customer touch-points
Automation Hub
AI to automate, increase STP, and save costs

Intelligent Document Processing
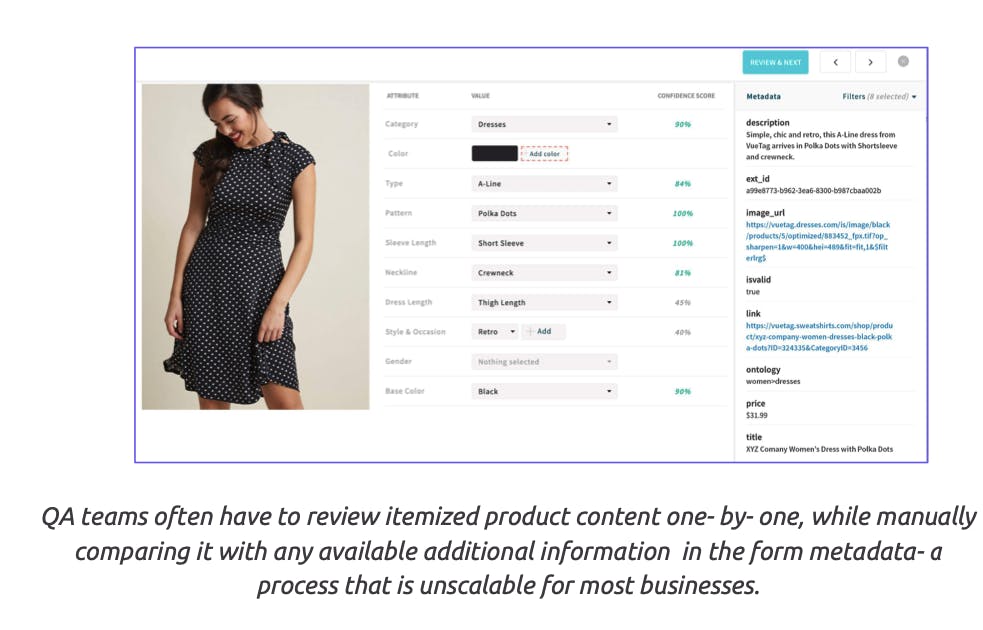
Unlock the value of unstructured data with automation

Workflow Automation
Identify and automate modules in any business workflow
Optimization Hub
Optimization strategies for improved business growth

Sales Efficiency & Optimization
Improve sales process efficiency using AI & automation

Lead Generation
AI-powered lead generation and assessment strategies

Excess Inventory Management
Sell Excess Inventory Faster To Maximize Recovery Costs
- Industries
Industries
Tailored AI and automation solutions for each industry

eCommerce and Consumer Retail
AI-powered experience management & automation suite

Insurance
Deliver friction-free insurance through AI & automation

Financial Services
Tailored AI and automation solutions for each industry

Logistics
End-to-end process management with AI & automation

Healthcare
Enhance Patient Experience with AI-Powered Process Automation
- Customers
- Partners
- Resources
Resources
Hooked on success? Our content will reel you in.

Blog
Think deeply. Read thoroughly. Subscribe intently.

Case Studies
Client successes, courtesy of AI

Podcasts
We talk to the best, bring you the crest. Hear us?

Reports
In-depth inquiries, insights for industry

Events
Shine in settings that whisper What's next?

Newsletters
A compass for the curious, if you will